


.svg)

.svg)
.svg)

Real Time Fraud Detection Using Apache Flink — Part 1

CEO & Co-Founder
.svg)
11 mins read


In a previous blog post we showcased how to get started with building a fraud detection application by creating fraud detection rules using the Java API.
In this blog, we’ll explore the pattern API to see how we can create fraud rules based on patterns. Although pattern API can be implemented in multiple ways, we’ll use SQL as it provides a way to understand the nuances of pattern API with little to no programming knowledge.
In fraud detection, you often need to identify a series of suspicious events over time — such as a sequence of small transactions followed by an unusually large transaction. Apache Flink’s Pattern API makes it easy to detect these complex event patterns in real time. Using pattern matching, you can define rules that scan through continuous data streams to catch subtle behavioral cues indicative of fraud.
An individual pattern is a basic sequence of events specified by certain conditions. Individual patterns serve as the building blocks for more complex pattern recognition scenarios. An individual pattern can either be a singleton or looping pattern. Singleton patterns accept one event whereas looping patterns accept one or more events.
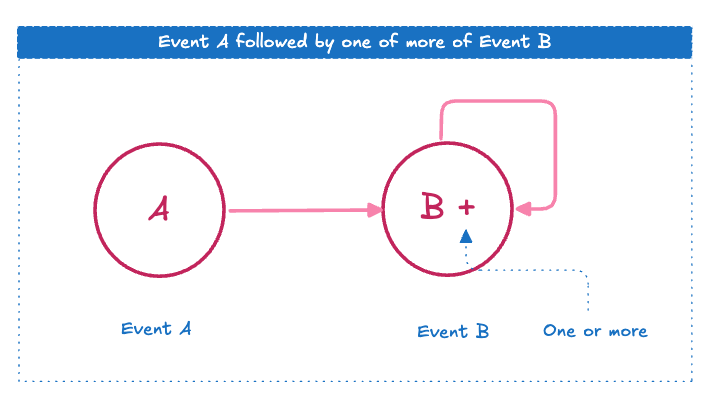
For example, consider the individual pattern A B+C, a simple way to represent an Event A followed by one or more of Event B.
Here’s another example C D? E — it’s similar to the example above with the difference that the ? is used to denote an optional event.

Simple patterns can be combined to create complex ones. For e.g. consider the pattern ((A B+) C D? E), which combines the 2 individual patterns we saw above.

Flink supports 3 different forms of contiguity between events when joining different patterns.
Groups of patterns take combination a step further by structuring multiple patterns under higher-level logic. For example we can alter the pattern in the previous section into 2 groups of patterns as follows
((A B+) | (C D? E))
This pattern can be explained as either event A followed by one or more event B’s or event C followed by an optional event D and terminating with event D. A match is generated if a sequence of events matches either of the patterns.
A match skip strategy tells Flink how to proceed once a match has been detected. Common options include
NO_SKIP: Every possible match will be emitted.SKIP_TO_NEXT: Discards every partial match that started with the same event, emits that last match.SKIP_PAST_LAST_EVENT: Discards every partial match that started after the match started but before it ended.SKIP_TO_FIRST: Discards every partial match that started after the match started but before the first event of PatternName occurred.SKIP_TO_LAST: Discards every partial match that started after the match started but before the last event of PatternName occurred.These strategies prevent overlaps or missed matches, ensuring precise and efficient pattern detection.
The Pattern API lets you declare a sequence of events (or conditions) that must occur in a specific order. In the diagram below we define a pattern as A+ B, it means that one or more occurrences of event A (e.g., small transactions) are immediately followed by event B (e.g., a large transaction). This pattern can help flag a fraudulent behaviour pattern where an attacker tests the waters with small amounts before attempting a large-scale fraud.

Pattern API can be implemented with multiple APIs like Java, Scala, SQL etc. For the purpose of this blog we are going to be using Flink’s SQL API.By using Flink SQL for pattern matching, you can define fraud detection logic in a declarative, concise, and readable manner. The enhanced readability makes it easier for engineers and analysts alike to understand and iterate if required.
Let’s take a quick look at the high-level architecture and flow of data before we dig deep.

Since this is a demonstration of the pattern API in Flink we create a simple pattern based rule
1. Custom transaction pattern: In this case we spot suspicious transactional sequences as they happen by small-amount transactions immediately followed by a sudden large transfer,between the same sender receiver pair.
2. Rapid-Fire Transactions to Many Recipients pattern: Detect if a user sends transactions to more than 3 distinct recipients within 2 minutes, possibly indicating suspicious “money mule” behaviour. Identify even if the transactions are small value transactions as this might be indicative of behavior to avoid detection.
3. High incoming Low retention pattern: The account received a high credit amount (above threshold) but 90%+ was transferred out within 24h.
In the first blog we setup a fraud detection application which does the following in order
For the pattern API we would be reusing most of the setup. We assume that there is already a datagen code running which is generating transaction data and publishing it to the transactions topic in kafka.
First lets start by opening the sql client. The SQL client can be opened by running sql-client.sh command in the job manager container.

Similar to the previous blog we assume that there is a kafka topic called transactions which has a continuous stream of transaction data flowing into it. Each message in the topic is a JSON string which contains transaction related fields. An example transaction would be as follows
{
"transaction_id": "2b792051-509c-4472-95af-598a94f612fa",
"user_id": 1003,
"recipient_id": 9004,
"amount": 1005,
"transaction_type": "credit",
"ts": "2025-02-03 17:01:12"
}
We can register the transactions input table by running the following command
create table transactions (transaction_id STRING,
user_id BIGINT,
recipient_id BIGINT,
amount FLOAT,
transaction_type STRING,
ts TIMESTAMP(3),
message_ts TIMESTAMP_LTZ(3) METADATA FROM 'timestamp',
proctime AS PROCTIME(),
WATERMARK FOR message_ts AS message_ts - INTERVAL '5' SECOND) WITH
(
'connector' = 'kafka',
'topic' = 'transactions',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = 'kafka:9094',
'format' = 'json'
);
At this stage there are some points to consider
1. Make sure you have the kafka connector jar corresponding to your flink version in the lib folder.
2. Make sure that the kafka broker address is according to your kafka setup. In this case the kafka broker is reachable on Kafka:9092 host port combination. This may vary according to your setup
3. The transaction data has to match table definition.
You can run a simple SELECT query to verify the table creation

We’ll define our first pattern based query to detect fraud as follows
SELECT
firstSmallTxnTime,
lastSmallTxnTime,
largeTxnTime,
largeTxnAmount
FROM
transactions MATCH_RECOGNIZE (
PARTITION BY user_id, recipient_id
ORDER BY
message_ts MEASURES A.ts AS firstSmallTxnTime,
LAST(A.ts) AS lastSmallTxnTime,
B.ts AS largeTxnTime,
B.amount AS largeTxnAmount ONE ROW PER MATCH
AFTER
MATCH SKIP PAST LAST ROW PATTERN (A+ B)
DEFINE
A AS A.amount < 1,
B AS B.amount > 1000
);
Note that the field by which to order has to be a time field and has to have a watermark. The watermark helps to handle messages which arrive at a delay. In this case the watermark is set to 5 seconds when we created the transactions table so utmost we accept messages with up to 5 seconds of delay.
The image below illustrates how to interpret the pattern in the code above

Running the above query results in a flink job which keeps outputting 1 record per pattern match. If you were able to successfully run you should be able to see an output similar to this

Here we specify a 5 occurrences in 5 mins as the threshold for rapid fire transactions
SELECT
user_id,
smallTxnCount,
firstSmallTxnTime,
lastSmallTxnTime
FROM transactions
MATCH_RECOGNIZE (
PARTITION BY user_id
ORDER BY message_ts
MEASURES
COUNT(A.recipient_id) AS smallTxnCount,
FIRST(A.ts) AS firstSmallTxnTime,
LAST(A.ts) AS lastSmallTxnTime
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A{5,}?) -- At least 5 occurrences of A
WITHIN INTERVAL '5' MINUTE
DEFINE
A AS A.amount < 10
);

The pattern here ends with B+? instead of just B+. Currently greedy quantifiers at the end are not allowed so by providing ‘?’ we can let the engine know when to end the pattern match
SELECT
depositSum,
depositCount,
withdrawalSum,
withdrawalCount,
depositStartTime,
depositEndTime,
withdrawalStartTime,
withdrawalEndTime
FROM transactions
MATCH_RECOGNIZE (
PARTITION BY user_id
ORDER BY message_ts
MEASURES
SUM(A.amount) AS depositSum,
COUNT(A.amount) AS depositCount,
FIRST(A.ts) AS depositStartTime,
LAST(A.ts) AS depositEndTime,
SUM(B.amount) AS withdrawalSum,
COUNT(B.amount) AS withdrawalCount,
FIRST(B.ts) AS withdrawalStartTime,
LAST(B.ts) AS withdrawalEndTime
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A+ B+?) WITHIN INTERVAL '1' HOUR
DEFINE
A AS A.transaction_type = 'credit',
B AS B.transaction_type = 'debit'
AND SUM(A.amount) > 500
AND SUM(B.amount) > 0.8 * SUM(A.amount)
);

The next step is to save our outputs to a new topic called fraudulent_transactions. We can do this by first creating a table in Flink SQL client corresponding to how the fraudulent transactions table should look like.
CREATE TABLE fraudulent_transactions (
transaction_id STRING,
ts TIMESTAMP(3),
fraud_type STRING
) WITH (
'connector' = 'kafka',
'topic' = 'fraudulent_transactions',
'properties.bootstrap.servers' = 'kafka:9094',
'properties.group.id' = 'flink-fraudulent-consumer-group',
'properties.auto.offset.reset' = 'earliest',
'format' = 'json'
);
We can now insert the detected fraudulent transactions into the output table by simply running an insert query and changing our fields to match the table format. The updated insert query becomes
INSERT INTO fraudulent_transactions
SELECT
transaction_id,
ts,
'custom_pattern' as fraud_type
FROM
transactions MATCH_RECOGNIZE (
PARTITION BY user_id, recipient_id
ORDER BY
message_ts MEASURES
B.transaction_id AS transaction_id,
B.ts AS ts
ONE ROW PER MATCH
AFTER
MATCH SKIP PAST LAST ROW PATTERN (A + B) DEFINE A AS A.amount < 1,
B AS B.amount > 1000
);

This query creates a continuously running job which runs in the backend. We’ll create the rules corresponding to the other patterns well.
INSERT INTO fraudulent_transactions
SELECT
transaction_id,
ts,
'high_incoming_low_retention_pattern' as fraud_type
FROM
transactions MATCH_RECOGNIZE (
PARTITION BY user_id
ORDER BY message_ts
MEASURES
LAST(B.transaction_id) AS transaction_id,
LAST(B.ts) AS ts,
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A+ B+?) WITHIN INTERVAL '1' HOUR
DEFINE
A AS A.transaction_type = 'credit',
B AS B.transaction_type = 'debit'
AND SUM(A.amount) > 500
AND SUM(B.amount) > 0.8 * SUM(A.amount)
);
INSERT INTO fraudulent_transactions
SELECT
transaction_id,
ts,
'rapid_small_transactions_pattern' as fraud_type
FROM transactions
MATCH_RECOGNIZE (
PARTITION BY user_id
ORDER BY message_ts
MEASURES
LAST(A.transaction_id) AS transaction_id,
LAST(A.ts) AS ts
ONE ROW PER MATCH
AFTER MATCH SKIP PAST LAST ROW
PATTERN (A{5,}?) -- At least 5 occurrences of A
WITHIN INTERVAL '5' MINUTE
DEFINE
-- 'A' represents small transactions
A AS A.amount < 10
);We can verify the results of the job by running a simple select on the fraudulent_transactions table.




Thus, we have successfully created a pattern based potential fraud detection rule which outputs to a kafka topic.
Incorporate machine learning algorithms and historical data. This allows for refined thresholds, predictive indicators, and the discovery of sophisticated fraud patterns that might go unnoticed by simpler rules. Future enhancements could include incorporating more advanced techniques like Statistical analysis, historical data analysis, graph-based algorithms and anomaly detection models to further improve detection accuracy.
Finally, we should look at integrating additional data streams or external services into our detection pipeline. This might include IP reputation data for other sources, user profiling information, or features from external online stores. Combining multiple data sources will help create a more robust and accurate fraud detection system.
While Flink SQL’s MATCH_RECOGNIZE clause is powerful for many scenarios, it can be challenging to implement highly specialized logic — such as dynamic thresholds, complex calculations, or external data lookups — using a purely declarative approach. The Java CEP API offers finer-grained control over state, timers, and event sequencing, making it well-suited for nuanced or highly customised fraud detection workflows.
Apache Flink provides a powerful, flexible foundation for real-time fraud detection. By combining robust stream processing with pattern recognition teams can quickly flag suspicious activity in a continuous flow of transactions. Whether you’re capturing simple sequences of small and large transactions or building sophisticated, ML-driven rules across multiple data streams, Flink’s event-time processing and stateful analytics enable a scalable, low-latency solution. As fraudulent behaviors continue to evolve, leveraging Flink’s pattern recognition capabilities allows you to stay ahead of threats and maintain trust in your platform.
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur.
Block quote
Ordered list
Unordered list
Bold text
Emphasis
Superscript
Subscript
.svg)
Stay in the know and learn about the latest trends in fraud, credit, and compliance risk.


.svg)
.svg)
.svg)
.webp)
.svg)
.svg)